/prod01/wlvacuk/media/departments/digital-content-and-communications/submitted-news-images/Wolves-Women-interview.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/submitted-news-images/CLS-cohort-2024.jpeg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/images-18-19/beinghuman_teaser.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/submitted-news-images/Espanyol-FC-exchange.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/submitted-news-images/Varsity.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/submitted-news-images/WMBF-business-festival.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/submitted-news-images/WUSCAs-Shortlist-tile-1.png)
Are your marking rubrics disadvantaging students?

Probably. Ours was. A case study.
I have run a popular final-year Clinical Psychology module for eight years, typically attracting around 100 students annually. Each year I anonymously collect my own end-of-module feedback so students can input to the module content. I felt this approach worked well; students could anonymously record what they liked or disliked about the module, and I would incrementally change things each year so that the module ran smoother, and students felt they had choice.
More recently, I began to think carefully about the performance of our marking rubric. Our summative assessment is a case study of a real person who was held in a Medium Secure Unit (MSU) in the West Midlands (anonymised). Students are taught to conduct a clinical formulation alongside a supporting psychological intervention and care package, mirroring the kind of work a clinical or assistant psychologist would carry out in practice. The rubric was designed to assess exactly these skills, and on the surface, it appeared to be working well. However, appearing to work and actually working are two different things, so I thought about testing this assumption statistically.
I used a Generalised Partial Credit Model (GPCM; Muraki, 1992) which is an Item Response Theory (IRT) approach (often used in educational testing) and I analysed whether each section of the rubric was actually doing what it was supposed to do. IRT is useful for answering questions such as 'Can this rubric reliably distinguish between a low-performing student, an average student, and a high-achieving one?
I tested 124 student responses (IRT does not require a power analysis) across seven rubric criteria (see Fig 1). Each marking criterion was evaluated on how well it was able to discriminate between students of different ability levels.
Level 6 Clinical Psychology Assessment Rubric
|
Assessment Criteria |
Exceptional (90 - 100%) |
Outstanding (80 - 89%) |
Excellent (70 - 79%) |
Very Good (60 - 69%) |
Good (50 - 59%) |
Sufficient (40 - 49%) |
Insufficient (30 - 39%) |
Poor (20 - 29%) |
|
Awareness |
||||||||
|
Demonstrate a critical understanding of the range of psychological problems encountered during clinical practice and evaluate them using psychological theories. This should involve reflecting on how different core domains of psychology might interact (e.g., attachment, developmental, cognitive etc). |
|
|
|
|
|
|
|
|
|
Assessment |
||||||||
|
Select and critically evaluate the appropriate assessment tools in relation to the case study. |
|
|
|
|
|
|
|
|
|
Formulation |
||||||||
|
Critically apply appropriate psychological terms and theories to a case study during the development of a clinical formulation. |
|
|
|
|
|
|
|
|
|
Identification of Appropriate Intervention |
||||||||
|
Analyse and critically evaluate the applicability of various psychological therapies to the range of psychological problems encountered in the case study. Be measured in your choice. |
|
|
|
|
|
|
|
|
|
Care Package |
||||||||
|
What are your recommendations post intervention to keep the client well? |
|
|
|
|
|
|
|
|
|
Empirical Evidence |
||||||||
|
Evidence of broad independent reading that details support for all sections (assessment, formulation and treatment recommendations). |
|
|
|
|
|
|
|
|
|
Overall Writing and Referencing |
||||||||
|
As a Level 6 student, you should be able to demonstrate a high standard of writing, paraphrasing and referencing. |
|
|
|
|
|
|
|
|
Fig.1 The L6 clinical formulation rubric.
Overall, the results showed the rubric demonstrated good psychometric properties. It reliably measured clinical competence across the ability range, and the statistical model fit the data well. However, while Overall Writing Quality and use of Empirical Evidence were the strongest performers in terms of distinguishing between our students, two key learning outcomes Assessment Tool Selection and the Care Package criteria were surprisingly, functioning less optimally.
Despite being core clinical skills that are taught and reinforced throughout the module, these domains struggled to differentiate between students of different ability levels. This suggests the problem may lie not in the teaching or the constructs themselves, but perhaps that the rubrics descriptors need more work.
From a measurement perspective, the Assessment Tool Selection and Care Package domains were introducing statistical noise into the grading scheme. Rather than contributing meaningful information about a student's clinical ability, these criteria were adding variability that was largely unrelated to actual performance differences making the overall, grade less precise than it should be. See Figure 2 for how these domains contribute to the overall rubric.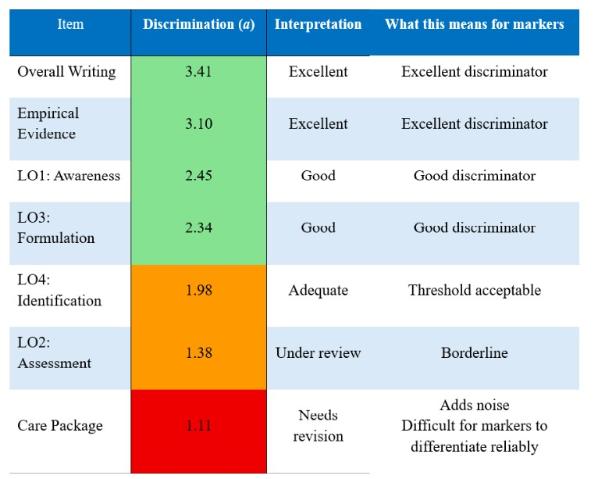
Note. a = Discrimination: how well the criterion distinguishes between students of different ability.
The analysis also revealed a ceiling effect in the rubric. The large majority of students were performing above the level at which the rubric begins. Students were easily bypassing the lower-tier grading domains and clustering around the midpoints. However, for higher-performing students, the rubric couldn't tell them apart. It was well-designed to identify students who were in the lower to very good range, but the rubric had difficulty recognising genuinely excellent work and above. See Fig 2 for ceiling effect plot and item precision.
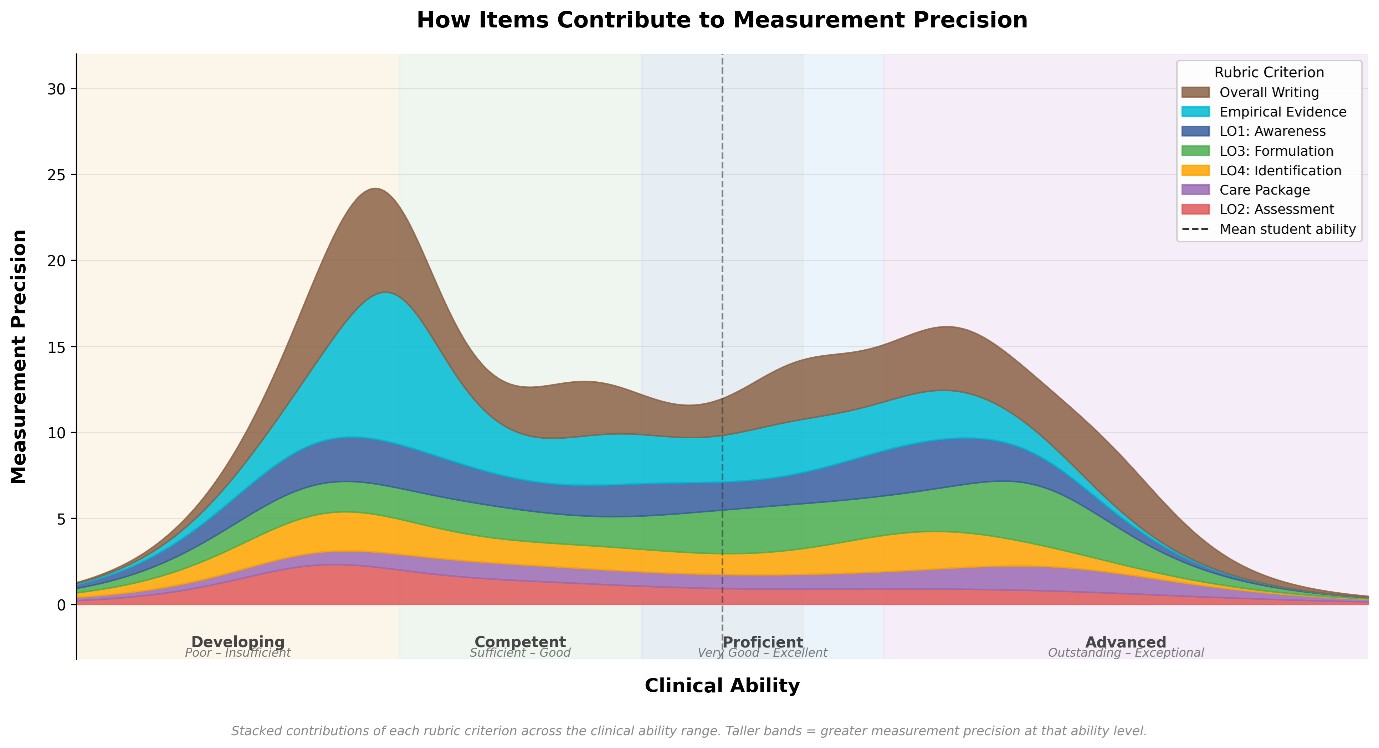
This is more common than you might think. Research in higher education assessment consistently highlights that upper grade descriptors (those distinguishing Very Good from Excellent) are frequently the least well-defined, making it difficult for graders to distinguish between adjacent high-performance categories consistently (Chan & Ho, 2019, as cited in Marrs et al., 2024; Brookhart, 2018). As a result, the highest categories tend to be awarded less frequently than student performance might otherwise warrant, and this appears to be a recurring limitation of rubric-based measurement tools more broadly.
Going forward, we plan to revise the two underperforming rubric domains by tightening the descriptors and making the language more specific. The aim is to raise the discrimination values (a) for Assessment Tool Selection and Care Package so that these criteria can better distinguish between students of different ability levels. Without this, these domains risk disadvantaging students whose clinical skills are simply not being captured accurately by the current wording. If successful, the revisions should improve both the marking precision and the clinical validity of the rubric as a whole. A re-analysis next year will confirm whether the changes worked.
Finally, I would argue that if you have implemented your own marking rubric and mapped it to university grade descriptors, it is worth asking whether it is working for your students or against them. You might think your rubric is working well (like we did), but without testing it statistically, you simply do not know.
About me: Dr David Boyda. I am a Senior Lecturer in the Department of Psychology, with research interests in lifespan trauma, masculinity, men's mental health, and suicide.
* Analysis conducted in Mplus and R (mirt package).
References:
Marrs, S., et al. (2024). Rubrics in higher education: an exploration of undergraduate students' understanding and perspectives. Assessment & Evaluation in Higher Education. https://doi.org/10.1080/02602938.2023.2299330
Muraki, E. (1992). A generalized partial credit model: Application of an EM algorithm. Applied Psychological Measurement, 16(2), 159–176. https://doi.org/10.1177/014662169201600206
Muthén, L. K., & Muthén, B. O. (1998–2017). Mplus user's guide (8th ed.). Muthén & Muthén.
Chalmers, R. P. (2012). mirt: A multidimensional item response theory package for the R environment. Journal of Statistical Software, 48(6), 1–29. https://doi.org/10.18637/jss.v048.i06
Brookhart, S. M. (2018). Appropriate criteria: Key to effective rubrics. Frontiers in Education, 3, 22. https://doi.org/10.3389/feduc.2018.00022
R: R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
For more information please contact the Corporate Communications Team.